隨著2023年國家網絡安全宣傳周的正式啟動,數據安全保護再次成為全社會關注的焦點。在本次宣傳周期間,眾多前沿技術集中亮相,其中,易保全區塊鏈技術以其獨特的優勢,為數據安全保護提供了全新的解決方案,堪稱在數據安全領域“上了一把牢固的鎖”。
在數字化浪潮席卷全球的今天,數據已成為關鍵生產要素和核心資產,其安全性直接關系到個人隱私、企業運營乃至國家安全。傳統的數據保護方式,如中心化存儲和加密傳輸,在面對日益復雜的網絡攻擊和數據泄露風險時,已顯露出一定的局限性。數據篡改、非法訪問、中心節點單點故障等問題,時刻威脅著數據的安全與完整性。
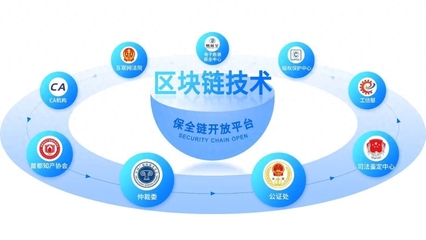
正是在這樣的背景下,易保全區塊鏈技術應運而生,為解決數據安全的核心痛點帶來了革命性的思路。區塊鏈技術本質上是一個分布式、去中心化的賬本系統,其核心特征包括不可篡改、全程留痕、可追溯和集體維護。易保全區塊鏈方案,正是將這些特性深度應用于數據安全保護領域。
它為數據“存證”與“溯源”提供了堅實基礎。任何數據一旦上鏈,其生成、傳輸、訪問、修改的全過程都會被精確記錄,并形成按時間順序鏈接的數據塊。由于每個區塊都包含前一個區塊的哈希值,任何對歷史數據的篡改都會導致后續所有區塊的哈希值失效,從而被網絡節點迅速發現并拒絕。這種機制確保了數據的真實性和不可抵賴性,為司法存證、知識產權保護、供應鏈追溯等場景提供了可靠的技術支撐。
它通過分布式存儲架構增強了數據的“韌性”。與將數據集中存放在單一服務器或數據中心不同,區塊鏈網絡中的數據由多個節點共同存儲和維護。這意味著即使部分節點遭受攻擊或發生故障,整個網絡的數據依然保持完整和可用,有效避免了中心化存儲帶來的單點故障風險,極大地提升了數據系統的抗毀性和服務連續性。
它在保障數據安全的也探索了數據“可用不可見”的隱私保護新范式。結合零知識證明、同態加密等密碼學前沿技術,易保全區塊鏈方案能夠在數據本身不被泄露的前提下,驗證數據的真實性或進行特定的計算。例如,在需要驗證用戶年齡是否成年的場景中,系統無需獲取用戶的具體出生日期,只需通過零知識證明驗證其“已滿18歲”這一陳述的真實性即可。這為數據要素的安全流通和價值釋放開辟了新的路徑。
在2023年國家網絡安全宣傳周期間,易保全區塊鏈技術的展示與實踐案例,生動詮釋了“網絡安全為人民,網絡安全靠人民”的主題。它不僅是網絡科技領域內一項重要的技術開發成果,更是構建清朗網絡空間、筑牢國家網絡安全屏障的關鍵工具之一。從金融交易到電子政務,從醫療健康到物聯網,其應用前景廣闊。
隨著技術的不斷成熟和法規標準的逐步完善,易保全區塊鏈技術有望與人工智能、物聯網等更多前沿技術深度融合,持續演化出更強大的數據安全保護能力。它代表的不僅僅是一把技術的“鎖”,更是一種全新的安全思維和信任構建機制,必將為數字經濟的高質量發展保駕護航,為全民共享安全、可靠的數字化未來貢獻核心力量。